
Data Synchronization
Data between cluster servers should be synchronized. Hanbiro builds four methods for this.
Data Synchronization
An simple way is that place some degree parallax between cluster servers, then automatically synchronize. This is really useful in case data and updated data or content is not much.
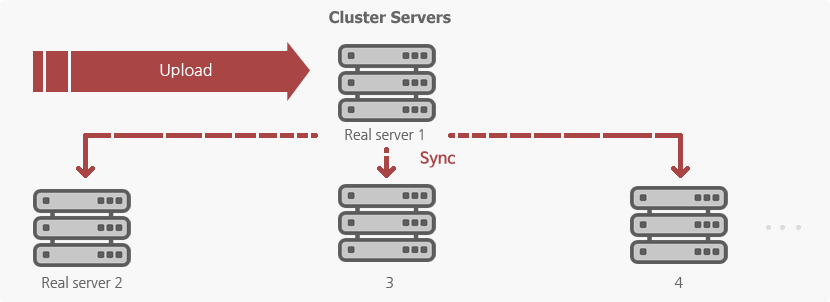
Data Uploading at a time
Hanbiro uses provided software to upload the data on Cluster Server at the same time . If there are any files that has been changed data by a program on the server, "Data Synchronization" method will be applied..

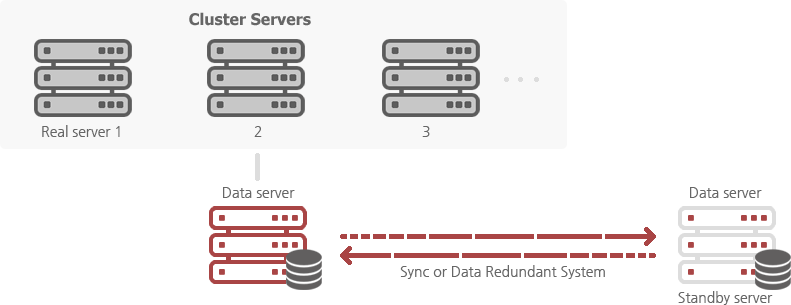
Data server
Subtract the data on a cluster server and operate separately. Configure the Fail Over system with redundancy or synchronization of the data server. If the data server has failed, automatically mount Data Server Standby Server to use. This is useful if the amount of data is less than 1TeraByte.
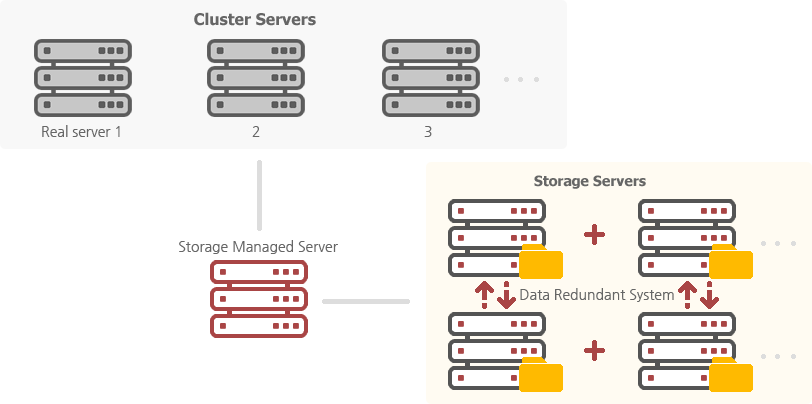
Storage of Data server
If the amount of data is a few TeraByte, Storage Server System must be configured. And in that case, there are many cases the file system is broken. You must configure the storage of Parallel File System. The server can be added according to the amount of data, and Failover must be configured as a redundant server configuration.