
MySQL Cluster
MySQL-NDB-Cluster-based configuration
Features
Necessity of MySQL Cluster
Limitations of extending MySQL-Replication: Because data entry and updates depends on the master server, when expending system, expansion of the slave server is easy, but expansion of the master server is somewhat constrained. When implementing clusters, server group of SQL-Node is implemented by each server that handles both data input/ output.
How to Implement
Require a total of three server groups(Node) for MySQL Cluster server configuration.
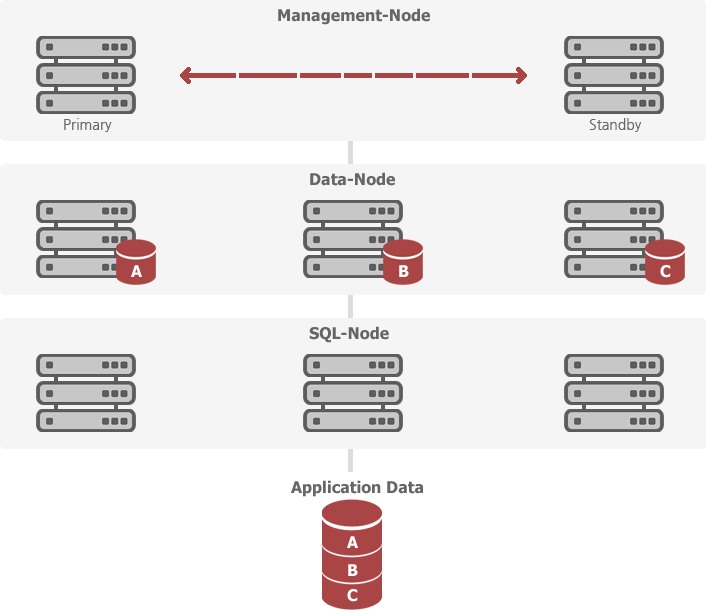
MGM-Node
Responsible for the overall management of the cluster configuration. Among Management Server, one acts as the Primary Server, and if failure occurs while working, missions will be carried out in Standby Server.Data-Node
They play a role in storing input database. All databases which are stored in each node are kept in memory to support a rapid response. (Habiro provides a proper memory.) It is possible to save the hard disc based on new released version, from MySQL5.1 or higher.(even create ndb based on disk, the column that contains the index is stored in the memory.)SQL-Node
Plays a role in responding to the request of the data of Data-Node Application or forwarding stored data to Data-Node.
MySQL- Replication-based configuration
Mysql-Dual-Master-Replication
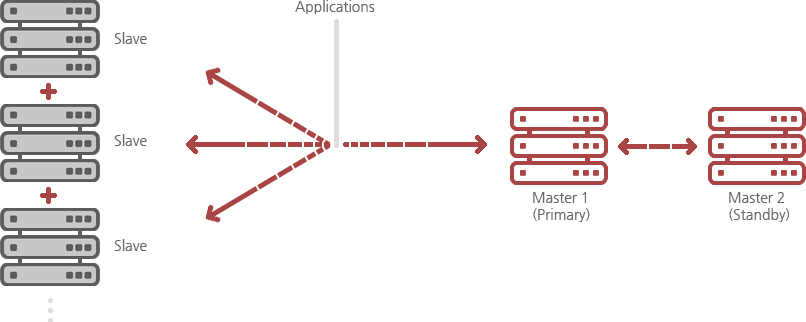
Mysql-Replication is used for real-time synchronizing data of MySQL server set as the master and data in a number of MySQL server set as Slave to backup and load balancing. Use it to configure the two master servers and when updating data, the technology can be applied equally to each of the master server.
Necessity of Dual-Master-Replication
Implementation method
Method 1
Because both master servers behave the same so when one of them has failed, the left server will continue to save the same data, and load can be distributed by application access.
Method 2
One of two master servers will act as the Primary Server and when an error occurs, missions will be carried out in Standby Server. Data input(Insert, Update, Delete) are done at both the master servers, Data Import(Select) is in charge of the slave servers, so Select query can achieve the best performance at many sites. Real-time data replication is possible, and has minimal impact on the server.